
Inom kort håller vi i samarbete med Seavus ett webinar på ämnet ”Arkivarien + Machine Learning – en perfekt match?” Seminariet vänder sig till arkivansvariga eller informationsansvarig. Datum: Onsdagen den 22 april, kl 12.15-13.15
Arkivarien + Machine Learning – en perfekt match?
Skribent: Leif Pettersson
Inledning
Det finns ingen brist på utmaningar i dagens arbete med att förvalta och bevara information som hanteras i digitalt format. Hur ska vi kunna hantera all den ”gamla” information som idag finns förvarad på olika filservrar, i e-postkonton, på olika separat fysiska media som USB-minnen, CD-skivor och DVD-skivor? Hur ska vi kunna få kontroll över den information som i allt större mängd skapas och används? Idag användes många formella, och informella, verksamhetsverktyg. Vanligtvis klagas det på att ”inget går att hitta något” samtidigt som det klagas på att det är så jobbigt att ange metadata – metadata som möjliggöra återsökning i ett senare skede?
Utmaningarna är mångfacetterade och ansvariga för att få ordning på informationen, bland annat arkivarier, står ibland lite handfallna. När du får uppdraget att ordna 5 miljoner filer på en filserver, ska ta emot 200 000 digitala filer från det stora infrastrukturprojektet eller sitter med 15 000 e-postmeddelanden som en före detta medarbetare har lämnat efter sig. Hur ska du ha möjlighet att få kontroll över dessa informationsmängder? Hur ska du säkerställa att nödvändig information kan tas om hand och få tillräckligt med metadata för att möjliggöra återanvändning, och i vissa fall bevarande?
Det finns en betydande teknisk skuld som oftast bara ”finns”. Vad är en teknisk skuld? Teknisk skuld uppkommer när en organisation väljer en lösning som snabbt löser en utmaning för stunden istället för att finna en mer optimal lösning som skulle har varit mer långsiktigt hållbar.
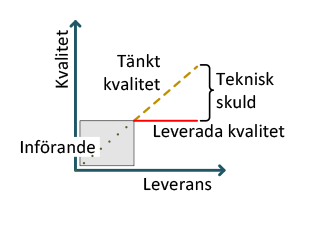
Information och data som är ostrukturerad eller som hanteras i gamla system ses oftast som en kostnad. Den kanske används mycket lite eller inte alls. Häri ligger en stor paradox – samtidigt är information och data bland det mest värdefulla många organisationer har.
Förutsättningar
För att vi ska kunna förvalta våra organisationers verksamhetsinformation behövs ett antal grundläggande förutsättningar. Liksom alla byggprojekt behövs en god grund att bygga på. Det måste finnas en modell hur vi värderar och strukturerar informationen, vi måste veta hur vi klassificera informationen, det måste finnas processer samt resurser och det måste finnas verktyg att hantera informationen i. Detta gäller oavsett i vilka format informationen hanteras. Exakt hur vi hanterar informationen kan dock skilja sig mellan olika format den är bunden i.
När en arkivarie ordnar pappersburen information stödjer sig denne på metoder som har utarbetats under mycket lång tid. Vi har våra sorteringsbord, våra arkivboxar och vår förmåga att med hjälp av vår yrkeserfarenhet snabbt få en grundläggande överblick. Vi öppnar en pärm eller en box och tar ut den bunt papper som de innehåller. Vi börjar bläddra genom de papper som ingår i bunten. Ofta räcker det med att se den övre högra tredjedelen av de handlingarna för att vi ska kunna göra oss en bild av vad just den här bunten kan tänkas innehålla. Vi kan ofta snabbt se att några av handlingarna i bunten avviker och inte hör hemma där. Vi ser också att de finns uppenbara handlingar ”av tillfällig betydelse” som vi kan plocka bort. Det kan räcka med att avvikande handlingar har en annan papperskvalitet. En erfaren arkivarie kan på så sätt kanske gå genom en eller fler hyllmeter varje dag och börja klassificera de olika informationsbuntarna. Det motsvarar mellan 4 500-5 000 sidor om det handlar om A4-papper.
Idag när vi börjar få uppdrag att på liknande sätt ta hand om olika kluster av information i digitala format tänker vi på samma sätt. Vi går in i filservern, eller säger att verksamheten ska gå in, där det ligger 100 000 handlingar i 13 000 mappar. Vi börjar med att manuellt försöka få en överblick av mappstrukturen. Vi ser att i den organisationsindelade mappstrukturen finns en mapp som heter ”Arkiv”. Vi öppnar den mappen och ser en annan struktur, uppdelad efter den tidigare organisationen. Här finns en mapp som heter ”Gammalt”. Vi öppnar den mappen, ytterligare en annan struktur, och så vidare. På måfå öppnar vi en mapp som heter ”Projekt” som ligger i mappen ”Gammalt”. Vi inser snabbt att den innehåller en stor mängd undermappar. Vi högerklickar på mappen ”Projekt” och väljer ”Egenskaper”. Det börjar räknas filer och mappar. Efter en stund framkommer att mappen innehåller 7 000 filer och 400 mappar.
Nu börjar den verkliga utmaningen. Det finns inga ”buntar” med information som vi snabbt kan bläddra genom. Vi tvingas att öppna mapp 1, dubbelklickar på fil 1 i mapp 1. Gör en bedömning av informationen och stänger filen. Vi öppnar sedan fil 2 i mapp 1. Gör bedömning på motsvarande sätt. Arbetet fortsätter fil för fil i den första mappen. Vi får ingen snabb överblick, vi får ingen taktil känsla och vi kan inte lägga våra digitala filer i virtuella högar på ett virtuellt bord. Vårt enda hopp står till de personer som en gång skapade mapparna och placerade filer i dessa att de var systematiska och noggranna. Att om en mapp heter ”Avtal” så ligger endast avtal i den mappen. Nu tillhör detta tyvärr undantagen.
En fil som kommer från en skanner kan heta ”S75A4025_2020-01-28_0540_001.pdf” – vad innehåller den för information? Du har en mapp som innehåller 200 filer med sådana namn heter ”EBA” och ligger i sin tur i en mapp som heter ”1001”.
Det finns säkert några som har lyckats ordna filservrar manuellt. Men det finns sannolikt fler som har försökt men inte har lyckats eller inte ens mäktat med att försöka. Det vanliga är att filservern inte innehåller 100 000 filer utan många hundra tusen, eller flera miljoner filer. Samtidigt vågar få rensa bort allt som är ”äldre än fem år” som ofta kommer som förslag från IT-avdelningen. Det sägs ”ja men ingen har tittat på det här de senaste fem åren…”. Det beror sannolikt på att det inte går att söka i filservern – vi letar efter det vi vet finns!
Jag ser ingen annan lösning för detta än att maskiner ordnar det maskiner har skapat. Vad menas med detta?
Lösningen?
Bara under de senaste 10 åren, med en accelererande innovationsrytm, har faktiskt maskiner med hjälp av algoritmer börjat kunna ”förstå” information som finns i olika digitala filer. Med ett antal verktyg och med hjälp från människor kan maskiner idag faktiskt hjälpa oss att hitta och klassificera information som förvaras i olika digitala filformat. Jag talar om artificiell intelligens och maskininlärning.
Maskininlärning (ML) är en delmängd av det som kallas artificiell intelligens eller AI. Arkivarier är väldigt skeptiska till detta och häri ser jag en paradox – jag vill hävda att just arkivarier är den yrkesgrupp i samhället som är bäst satta att faktiskt hjälpa övriga samhället att lösa detta tillsammans med de innovatörer som arbetar med maskininlärning idag.
Just ML kräver, för att fungera bra, att det finns beskrivande data som applikationerna kan utgå från för att börja analysera en viss mängd information. De måste gå i skolan innan de kan påbörja sitt arbete. När det skrivs om AI och ML tas det här steget upp som en av de större utmaningarna. Jag vill hävda att detta är utmaningar som arkivarier alltid har arbetat med och att få är bättre lämpade att ta fram övningsdata för inlärning. Vi arbetar med dokumenthanteringsplaner, hanteringsanvisningar, gallringsutredningar. Vi samlar på oss ritningsförteckningar, kodplaner och styrfiler, telefonkataloger över gamla organisationer. De av oss som har börjat arbeta med e-arkivering har även börjat förstå och kunna ta ut beskrivande data ur olika verksamhetssystems databaser. Vi har kort sagt alla förutsättningar att skapa det läromaterial som krävs för att kunna använda AI och ML. Börjar det inte bli tid för oss att ”visa världen” och gå i bräschen?
Att våga börja
Finns det någon där ute som skulle våga göra ett försök? Jag kan inte se att det finns något att förlora! På sätt och vis ser jag ett intressant partnerskap här. Historien möter framtiden i en symbios.
Här har framtiden ett uttalat behov av att lära sig av historisk information och samtidig kan historisk information få hjälp av framtiden för att bli tillgänglig.
ArkivIT har påbörjat ett samarbete med företaget Seavus (https://seavus.se/tech-trends/artificiell-intelligens) för att börja utveckla verktyg och processer som kommer att hjälpa arkivvärlden att få större kontroll över de informationsmassor som brukar betecknas som ostrukturerade. Exemplet med det digitala arvet (eller teknikskulden) filservrar är bara ett scenario. Vi ser andra områden där arkivvärlden och AI-området kan få stor betydelse för hur vi förvaltar vår information i framtiden.
Redan idag arbetas det med verktyg för att hantera e-post, att kunna anonymisera information och data, samt att få en ökad grad av automatiserad klassificering och gruppering av information. Jag ser andra områden där de här verktygen kan få betydelse.
Ett exempel – vi skulle kunna använda maskininlärning för att få kontroll på viktig information som inte hanteras efter till exempel informationssäkerhetsföreskrifter och/eller hanteringsanvisningar. De flesta organisationerna har flera olika verktyg de använder för sin hantering idag. Det kan finnas regelverk som reglerar att sekretessbelagd information endast får hanteras i organisationens dokument- och ärendehanteringssystem. Samtidigt hanteras den typen av information på filservrar eller olika externa tjänster för att det är bekvämt eller på grund av okunskap. En ML-applikation skulle kunna ligga och bevaka dessa icke tillåtna plattformar för att fånga den typen av information. Det unika med maskininlärning är att den inte är beroende av mappnamn, filnamn eller eventuella metadata. Den analyserar den faktiska texten i filerna och kan hitta sammanhang som gör att den klassar informationen som sannolikt sekretessbelagd. Antingen litar vi på lösningens bedömning eller så får en människa sedan göra den slutgiltiga bedömningen. Efter beslut kan informationen läggas över i det rätta systemet och hanteras i detta. I nästa processens nästa steg, antingen direkt eller efter en bedömning av en person, kan den information som hittas föras över med hjälp av processautomation till valda verktyg för organisationens informationshantering.
Frågan är nu – finns arkivarien där ute som är villig att kliva in i den här nya spännande världen och få den hjälp som ni alla förtjänar, och som jag tror, många av er behöver? Att påbörja en avbetalningsplan för gamla teknikskulder? Att komma närmre en lösning på den stora utmaningen – ”If only we knew what we know”[1].
[1] Carla O’Dell & C. Jackson Grayson Jr; ”If only we knew what we know”, 1998
Om artikelförfattaren
Leif Pettersson är utbildad arkivarie med tidigare erfarenhet från museivärlden, arbete inom lokaltrafikorganisation samt konsult inom området informationshantering/ informationsarkitektur. Därtill har Leif arbetat som bevarandestrateg vid Stockholms läns landstingsarkiv där han fick en bred kunskapsbas samt vana av att arbeta i gränslandet mellan verksamhet och IT-avdelning. Leif är generellt intresserad av människor och hur vi använder samt hanterar information. Speciella intressen är teknisk dokumentation, digitala filformat samt informationshantering i verksamhetssystem (ECM). Utöver arkivarie-studier har Leif även studerat historia.

Webinar: Arkivarien + Machine Learning – en perfekt match?
– Öppna upp verksamhetens outnyttjade informationsberg
Datum: Onsdagen den 22 april, kl 12.15-13.15
Dagens verksamheter har en informationsskuld i form av en oöverskådlig dokumentmängd som hittills har varit omöjlig att hantera. Med Machine Learning har nu öppnats nya möjligheter.
ArkivIT arrangerar tillsammans med Seavus ett webinar där vi fördjupar oss i denna enorma mängd dokument som inte kan sökas eller återanvändas med tillhörande bundet värde eller till vissa delar skulle kunna gallras men måste nu hanteras och genererar onödiga kostnader.
Under webinaret kommer vi att demonstrera några exempel på tillämpningsområden som skulle rädda dagen för många medarbetare och organisationer.
Målgrupp
Seminariet vänder sig till arkivansvariga eller informationsansvariga inom organisationer med stora ostrukturerade informationsmängder i digitala format som behöver struktureras, kunna återfinnas och inte minst – gallras.
Anmäl dig här
Anmälan sker via Eventbrite. Efter att du gjort din anmälan skickas bekräftelse e-post inklusive länk till den digitala sändningen till din angivna e-postadress.
Kontakta oss
Fann du ovan ämne intressant och vill höra mer om hur vi tänker och kan assistera er organisation på området? Hör gärna av dig via nedan kontaktformulär så kan vi prata vidare.






