
”Det är ändå bara arkivarien som ska söka…” av Peppe Pettersson
Jag vet inte hur många gånger jag har hört ovanstående kommentar när ett e-arkiv ska implementeras. Här ligger kärnan till en av arkivens och forskningens största utmaningar framåt.
Redan 2017 kunde två författare konstatera att NARA (National archives and records administration) i USA fram till det året fångat in över 300 TB med inkommande och utgående e-postmeddelanden hämtade från Vita huset. De kunde också konstatera att arkivet fortsatt arkiverade dessa e-postmeddelandena trots att det inte fanns någon strategi eller plan om, hur eller när dessa skulle tillgängliggöras.1
Det här är något som pågår och har pågått i många år globalt. Vi fångar och arkiverar otroliga mängder data och information, men ytterst lite finns tillgängligt. De finns ofta inte ens tillgängliga på plats i arkivet, i biblioteket eller på museet för allmänheten. Förr eller senare kommer detta att ifrågasättas. Varför lägga resurser på något som inte används eller som det inte finns planer för hur det kommer att användas?
Om vi som arkivarier tänker igenom vad vi lägger vår arbetsdag på så ser vi att vi koncentrerar oss på att främst fånga, arkivera och bevara information. Vi har normalt inte lika stort fokus på att användarvänligt tillgängliggöra den information som vi hämtar in för att bevara. Observera att jag här endast omnämner arkivarier, inte bibliotekarier eller museitjänstemän. Här råder en väsentlig skillnad i utgångspunkten mellan exempelvis arkivvetenskapen och informationsvetenskapen.
Inom informationsvetenskapen finns ett stort fokus på att information ska vara strukturerad samt registrerad på ett sätt så att det underlättar för en användare att hitta och upptäcka samband mellan olika informationssamlingar. Det finns därför mycket skrivet inom informationsvetenskapen om hur detta görs på bästa sätt. Idag har även datavetenskapen börjat intressera sig för det som kallas sökbarhet i samband med den otroliga utveckling som sker inom artificiell intelligens.
I inledningen nämner jag e-arkiv. En majoritet av den information som idag skapas i digitalt format kommer sannolikt endast att vara tillgänglig via olika e-arkivlösningar. Även om det bara är arkivarien som ska söka så måste fortfarande sökbarheten vara funktionell och kraftfull. Här ser jag två stora utmaningar idag.
I de svenska kommersiella e-arkivlösningarna, men även i e-arkiv som bygger på öppen källkod, upplever jag en ganska mager sökfunktionalitet. Den funktionalitet som finns begränsas ofta, exempelvis genom att full fritextsökning inte aktiverats för att den ”tar för mycket kraft” från systemet.
Idag används i princip endast en typ av sökning i e-arkiven. Den presenterar ett begränsat urval av sökfält där vi skriver sökbegrepp, väljer från vallistor och/eller datum. Vi söker då på den metadata som finns inläst om de olika arkivobjekten som hanteras i systemet. Om kvaliteten brister på den metadata vi söker i blir sökresultatet därefter. Om jag frågar om det går att fritextsöka svaras det vanligen ”ja”. Om jag sedan frågar om det går att fritextsöka i all text som hanteras i lösningen inklusive i arkivobjekten blir svaret oftast ”nej”.
Med fritextsökning menar många sökning i metadata. När en sökning är gjord och vi får träff(ar) presenteras resultatet i en träfflista med ett förutbestämt antal kolumner och länkar till arkivobjekten. Vanligen går det att sortera en kolumn men aldrig i två eller fler som exempelvis i kalkylfiler.
Om jag får så många träffar att jag måste skrolla ned försvinner kolumnrubrikerna. Vanligen presenteras en träfflista där du även måste skrolla i sidled och då försvinner den viktigaste kolumnen – vilket arkivobjekt en rad handlar om. Det får till följd att om du skrollar till höger och nedåt vet du inte vilket arkivobjekt som representeras på en rad samt du kanske inte vet vad värdet i en cell på raden är för typ av metadata.
”Hur vanligt är det inte att den som söker faktiskt inte riktigt vet vad den efterfrågar.”
Ponera nu att du snabbt vill se vad ett arkivobjekt är och klickar på en den länk som visas. I bästa fall visas nu en förhandsvisning av objektet i träfflistan vilket är ovanligt i svenska system. Annars visas objektet i den webbläsare du har öppnat lösningens gränssnitt i om just den webbläsaren stödjer just det filformatet. Om inte laddas filen ned lokalt till den dator du använder och då får du leta fram filen och hoppas att datorn har en programvara som kan öppna filen.2
Jag vill hävda att även om det ”bara är arkivarien” som ska söka så måste våra e-arkivlösningar ha betydligt vassare sökmöjligheter. Hur vanligt är det inte att den som söker faktiskt inte riktigt vet vad den efterfrågar. Om det då endast går att söka på ett fåtal metadata, hur ska arkivarien kunna hjälpa?
Det finns ett antal sätt att utöka sökbarheten. Det som har arkiverats bör kunna visualiseras med de strukturer som de olika arkivobjekten ligger i. Det kan vara allmänna arkivschemat, processbaserade strukturer, informationsmodeller för teknisk dokumentation, arkivbildarens organisationsstrukturer, etcetera.
Ett exempel är en visualiseringsteknik som kallas för fasettering. Det är i grunden en filtrering som görs av metadata baserat på vad du har sökt efter. Den data som används är den indexerade metadata som finns i en lösning. Den absolut vanligaste fasetteringen vi stöter på är när vi exempelvis ska handla skor på nätet. Vi är inne på en webbsida och kanske söker efter ett par finskor. Du får ett sökresultat med ett antal skor. Till vänster får du också en möjlighet att välja material, märke, etcetera. Det är en fasettering som gjorts.
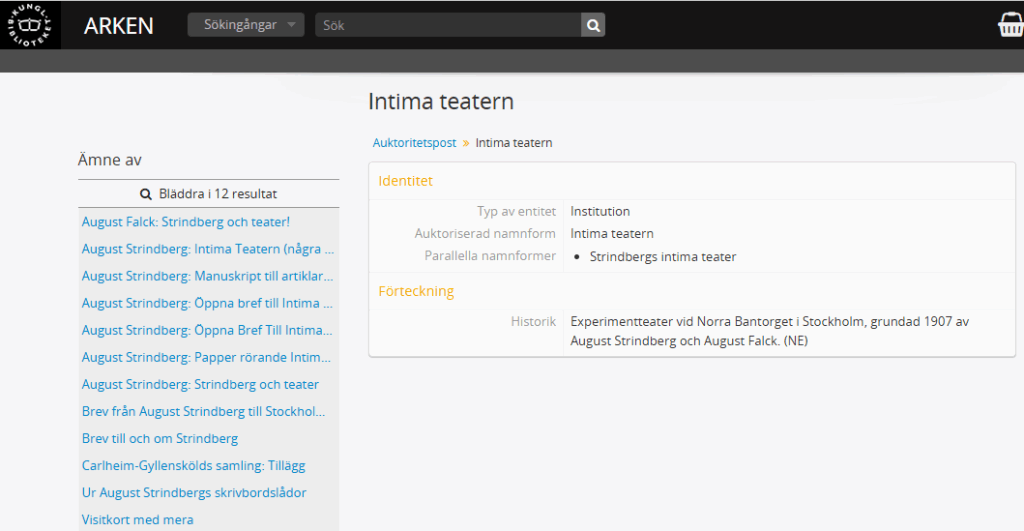
Hur detta kan se ut för ett arkiv kan ses i Kungliga bibliotekets hemsida för personarkiv och speciella samlingar: Arken.3 När en sökning på Intima teatern görs får användaren även se andra delar av arkivet där Intima teatern omnämns.
Att genomföra forskning i en allt mer digital värld är som att försöka navigera i ett landskap som ständigt förändras. I den världen finns det en växande utmaning – vi hittar endast det vi söker efter.
Påståendet kan tyckas vara märkligt men det är kanske en av de största utmaningarna, om än en av de minst omtalade, inom arkivvärlden och forskarvärlden. Även om en sökning i ett e-arkiv oftast är bristfällig, kan det på ytan ändå ses som praktiskt. Vi slipper sitta och bläddra genom högar av pappershandlingar och ödsla tid på detta. Men denna praktikalitet gör att vi förlorar något som jag inte tror ska underskattas – vi förlorar möjligheten till serendipitet.
Det finns ingen riktigt vedertagen definition för vad serendipitet är. Det handlar om när vi finner något oväntat men värdefullt när vi söker efter något annat. Vissa likställer serendipitet med ”chans” men det är något mer än bara att ha tur.4 Det börjar med tur eller en chans men den person som får det måste ha en grad av kunskap som gör att en insikt kan uppnås – en epifani.
Inom naturvetenskaperna finns en växande oro att forskningsstuderande och yrkesverksamma naturvetare har börjat använda datorer och digital data för mycket. En rad stora upptäckter och uppfinningar som vi använder idag har sin grund i serendipitet med följande epifani. Allt från Arkimedes i badet (”Eureka!”), Isaac Newtons äpple, till penicillinet och kardborrbandet. När den fysiska omvärlden inte längre ingår i forskningen minskar sannolikheten för nya plötsliga insikter högst väsentligt.
”Risken är att kanske den viktiga egenskapen – att vara nyfiken – inte får informationsbränsle och väcks.”
Precis det fenomenet vill jag hävda riskerar att hända även när forskare ökar sitt fokus mot data och information i digitala format. När material i arkiv används för att finna information kring en frågeställning är detta oftast en iterativ process. När vi tidigare gjorde efterforskningar i arkiv och kanske sökte efter specifika dokument eller rent generellt försökte sätta oss in i ett arkiv fick vi bläddra i papperssamlingar. Resultatet av den aktiviteten kunde bli att informationen vi fick till oss genom detta ändrade den ursprungliga frågeställningen. Det kunde rent av leda till att helt nya frågeställningar uppkom och eventuellt till helt nya forskningsområden.
Utmaningen kring detta är mångfacetterad. De exakta sökningarna gör att vi får en sämre förståelse för de sammanhang som vi kan få syn på när vi bläddrar genom ”onödiga” papper. Övergripande språkbruk, handstilar, typ av papper, antecknar i marginalerna med mera ger oss merinformation. Risken är att kanske den viktiga egenskapen – att vara nyfiken – inte får informationsbränsle och väcks. Finns det en risk att när den taktila känslan av att bläddra i papper och se visuella ledtrådar försvinner dämpas också fantasin? Att göra efterforskningar i arkiv handlar ofta om att pussla ihop delmängder till en konstruerad helhet. Risken är uppenbar att vi får en enkelriktad ”linjär” berättelse i stället för flerskiktiga tolkningar.
Det finns ytterligare en facett i min oro. Förutom att vi får ett svar på en sökning så fungerar de söktjänster som används idag på olika sätt. En sökfråga kan få olika svar från samma textmaterial beroende på vilken sökmotor som används. De är inte neutrala eftersom de använder algoritmer skrivna av olika människor. De indexerar text och rankar svaren på olika sätt. Det gör att vi får ett urval som vi inte själva har kontroll över.
Det finns även andra risker. Förmågan att läsa skrivstil har i princip försvunnit hos yngre idag. Liksom många andra akademiska aktiviteter ingår också ett element av hantverk när vi forskar i ett pappersbundet arkiv. Den kunskapen riskerar att försvinna över tid.
Rent generellt sker en slags epistemologisk förskjutning gällande hur kunskap skapas eller uppnås. Algoritmer, datatransformering och att kunna söka i databaser blir de nya förutsättningarna för att kunna forska och detta kommer naturligtvis att förändra exempelvis hur historia skrivs i förlängningen.
Jag hoppas att det kommer lösningar för att möjliggöra serendipitet även inom den digitala världen. Så att vi inte förlorar komplexiteten, rikedomen, nyfikenheten och den magiska känslan som uppstår när den där fantastiska upptäckten görs som ger dig en insikt som en blixt från klar himmel och du kan utbrista – EUREKA!
Fotnoter
[2] Observera vilken informationssäkerhetsrisk detta kan bli. De filer som laddas ned ligger sedan kvar lokalt på datorn.
[3] Se https://arken.kb.se/
[4] Se exempelvis – https://www.tandfonline.com/doi/full/10.1080/0309877X.2021.1905157
Leif “Peppe” Pettersson
Roll/yrke: Arkivarie
Arbetsplats: ArkivIT
Har arbetat som arkivarie i drygt 30 år och har genom åren haft fokus på informationshantering inom organisationer och hur vi använder information- en i vårt dagliga arbete. De senaste åren har Peppe främst arbetat med olika aspekter av digitalt bevarande